
15 simple AI image prompts that stump chatGPT

Introduction:
The other day I ran across this ad for Chatgpt:

This ad is bullshit. Chatgpts new image generation model is highly impressive, and it can create a large range of images with surprising accuracy. But it absolutely cannot create “any image” for free. There’s a little fine print of “restrictions apply”: but if you use the word “any”, you are implicitly stating there aren’t restrictions, or at least not reasonable ones.
To celebrate OpenAI’s latest foray into false advertising, in this post I will show Chatgpt’s failed responses to 15 simple prompts, and explain why each fails, and what we can learn from this.
In the next two sections, I will talk about the methodology and the ethics of this cheap experiment. Feel free to skip these sections if you don’t care.
Methodology:
For the sake of this post, I’m just going to check if the AI can make the image directly as a result of a simple prompt. It is possible that an AI image matching some of the prompts could be created with extensive and clever AI prompting or just spamming the request enough times. I’m not the best prompter in the world and i’m working with the free version of chatgpt, so testing this simply isn’t a good use of time.
My criteria for failure was to ask the prompt to chatgpt two seperate times in two seperate context windows. If both attempts were failures, I did one last test: I explained in detail what the last attempt had done wrong, and then asked GPT-4o in reasoning mode to rewrite the prompt to correct the issue, and generate one more image. If that failed to, I declared the prompt failed.
To start with I had about 30 different prompts written that I guessed might be difficult for the AI. About 10 of these actually ended up producing a correct image in some stage of the above methodology. Of the 20 failed prompts, I picked 15 interesting ones for the sake of interest.
Ethics:
I am not against AI image generation in theory, but I am against how it is currently practiced: scraping the whole internet to steal images without compensation or credit, feeding them into the machine, and then releasing them out to undercut the pay of the artists who had their work stolen. I do not endorse these practices, and in general I will not use AI images for non-research purposes. I also did not purchase chatgpt-pro for this post: they still have not gotten any money from me.
I am also concerned about the climate impacts of AI. However the cost of individual use is not particularly high. One estimate put a median cost of 500 Wh for generating a thousand images. So the about a hundred images I generated for this post used approximately 50 Wh, equivalent something like half an hour of laptop use. To offset this, I reduced my screen time by a few hours this week.
I justify this blog post because it is important to have an accurate understanding of what AI can and can’t do. I hope that the puncturing of openAI bullshit will help stop people from trusting everything they say, and I hope to put AI skeptics on a better factual grounding for future debates.
Results:
Generate an image with the prompt “A man sitting on a woman’s shoulders, both spinning sock poi in daylight“

Sock poi is a circus prop, the simplest form of which is a ball stuffed into a long sock, which you spin around.
The key point here is that when actual poi is being spun, one end of the poi should be held in the hands: and the shape of the poi will almost always be exactly straight, held out by centrifugal factors, as in this still from a poi video:

The AI image fails this, warping the poi into a weird angle, while for most of them the poi isn’t being held properly. I presume this is because most of the images it sees of poi is of it in motion. Also, the woman’s hand on the right is extremely fucked up, and looks kinda like a foot.
Generate an image with the prompt “An accurate picture of a DVORAK keyboard with the “V and K” keys swapped with each other“

The layout of keys is mostly correct, but the labelling of the keys is all over the place. Pretty much all the letters are in the wrong place, and the letter Q is repeated 5 times for some reason.
Generate an image with the prompt “A labelled diagram of the human eye“
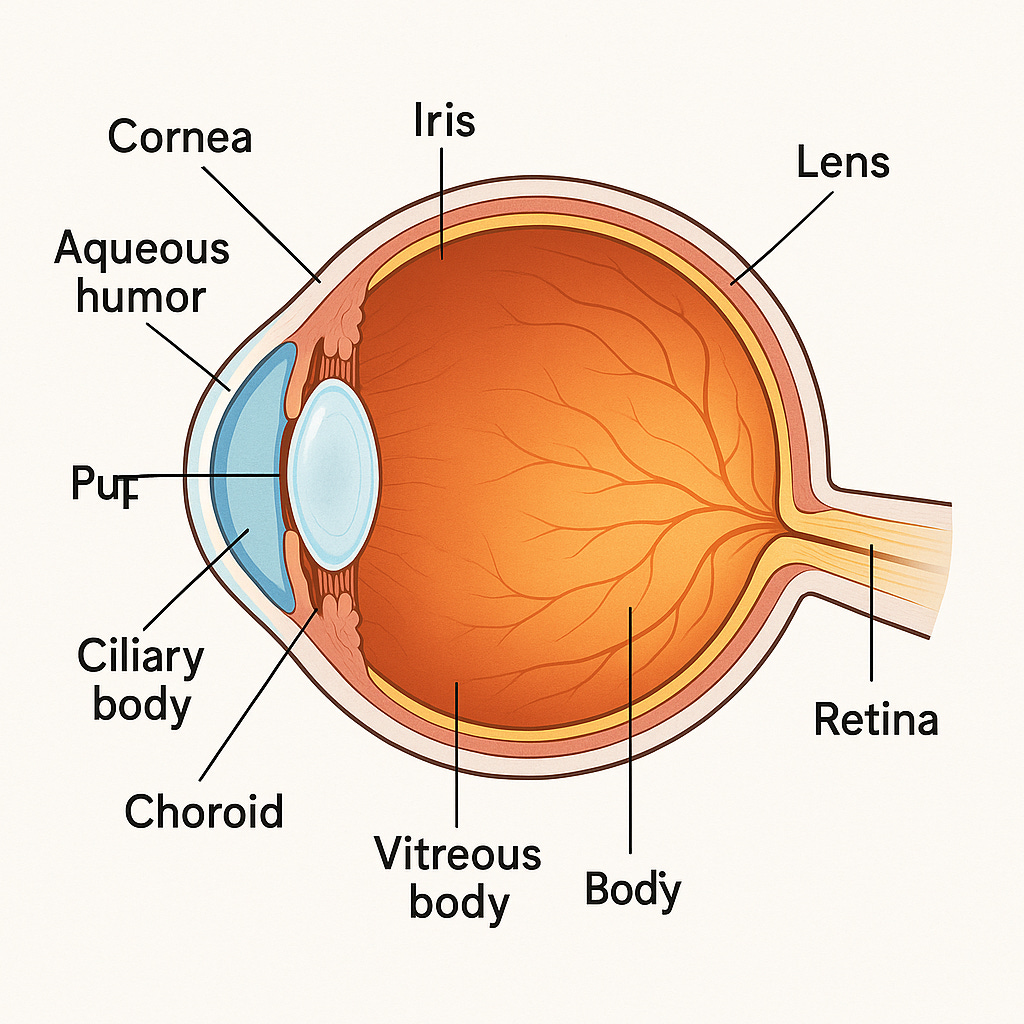
This image has some weird text issues, but the main problem is that the labels don’t match up to the correct parts at all. Look at the “lens” which is claimed to be at the back of the eye.
The AI knows what an eye diagram is meant to look like, and it even knows what type of labels are meant to be on such a diagram, but it doesn’t understand what the arrows from label to “part of the eye” are.
Generate an image with the prompt “A detailed image of a house party with dozens of people“

This is one that looks normal at first glance, and the people at the front of the picture look okay (although there seem to be three sets of identical twins for some reason). When you zoom into the background, it all falls apart:

Generate an image with the prompt “A picture of a nearly finished jigsaw puzzle of a castle, with the remaining 3 pieces next to it. The whole puzzle should be visible“

The AI gets what a jigsaw puzzle looks like, and has a perfectly fine image on it. But it doesn’t understand that a “nearly finished jigsaw puzzle” has holes in it. In addition, the outer puzzle pieces are too large, and some of the joins between puzzle pieces just dissappear.
Generate an image with the prompt “A detailed wheres wally page“

This is another case where the AI just can’t handle the number of people it’s trying to depict, and also doesn’t quite get the concept of what is required for a where’s wally page. I think I found wally though:

Generate an image with the prompt “A 5 panel instructional page on how to make toast“

This is a good effort, and you can tell they put a lot of effort into getting multipanel comics working: there aren’t even any mistakes in the text. Unfortunately, it got befuddled by the “5 panel” request and made 6 instead: it also failed at consistency between panels, with levers and toast randomly appearing and disappearing.
An attempt to prompt it fixed the number of panel issues, but turned the buttons and dials into being made of toast.
Generate an image with the prompt “A group of about a dozen people spelling out “OPEC” lying down with their bodies“

Yeah, I’m just going to move on and pretend I didn’t see that.
Generate an image with the prompt “A picture of exactly 23 rocks arranged randomly“

Counting is not an image generating AI’s strong suit. It generated 2 rocks too many, and failed again when I pointed this out.
Generate an image with the prompt “A photo of a secret service member doing a backflip off the presidential podium”

First, that presidential seal has messed up text and has erased the american eagle entirely:

Second: THE GUYS EYELIDS ARE UPSIDE DOWN. Creepy.
generate an image of a very wide glass and a very thin glass which are each filled with the same volume of wine.

This one’s kinda mean, honestly. AI is notoriously bad at depicting wine glasses that aren’t half full, and here I’m adding in the twist of expecting it to do 3d reasoning. The height of the wine in the wide rimmed glass should be much, much lower.
Generate an image with the prompt "a before and after image of a lego sunflower, with the left half being the individual pieces and the right half being fully constructed"

The design of a lego sunflower is way too simple for an actual lego product, and you can see there’s no real way for everything to fit together. Furthermore, you can look at the constituent parts on the left and see that they don’t add up to the parts on the right.
Trying to prompt it to improve the matching of parts just resulted in reducing the number of pieces on the left: they still did not match.
Create an image with the prompt: “a full board top down image of a legal chess game in the midgame where a white bishop is checking the black king”

GPT can make images of chess games, but it has difficulty understanding game concepts like “checking the king”. It also frequently puts pieces in impossible places, like the pawn on c1. Also, I don’t know what’s going on with the arrow shaped piece lying on the board.
Generate an image divided into 4 panels, showing the exterior of the same church from the different viewing angles of top, front, back and side.

This is a lot better than I expected, and the top two images almost sorta match up apart from the number of windows at the top. But then the back does not work at all: there is no sign of the tilted roof in any of the other images.
Generate an image with the prompt "5 people standing on the ground holding out one hula hoop each to form the olympic games symbol"

This one is quite a mess. It doesn’t understand the whole “1 person per hoop thing”, doesn’t get the colours right, and the hands are horrifyingly fusing to the hoops or unnaturally twisted. GPT seems to want to enforce the olympic shape by having hoops hover in midair.
What does GPT fail at:
GPT currently struggles in many different areas.
First, it struggles with exact numbers, especially exact large numbers.
Second: it struggles with large numbers of people.
third: it struggles with unusual or acrobatic human poses.
fourth: it struggles with exact text (although it’s gotten a lot better).
fifth: it struggles with consistent 3 dimensional reasoning.
sixth, it struggles with precision tasks like labelling diagrams.
seventh, it struggles with prompts requiring outside knowledge, like the rules of chess.
It wasn’t too difficult to come up with these prompts: roughly 2/3rds of the prompts I though might stump GPT ended up doing so. The main key is to try to think of things that can’t be easily mix and matched from elements with large amounts of available labelled data. For example, there are a lot of images of lego sunflowers on the web, but not a lot of pictures of their individual components.
Final image:
Now, I anticipate that someone might decide that this is not sufficient rebuttal of the claim that AI can make “any image”. After all, I only tried each prompt three times, so it’s possible that by skilled prompting and enough regeneration someone could make images matching the prompt. This is definitely true of, say the 23 stones: if you generate enough images, one of them will have the right number eventually. I think it should be possible to get the “dobule sock poi” as well.
So to make a prompt that I am certain cannot be created with AI alone, no matter how hard you try… I just combined all of the prompts above into a megaprompt:
Generate an image with the following prompt: “a large, photorealistic image of room with many activities occurring. In the front of the image is a long table with many objects: There is a jigsaw puzzle on a table that is nearly finished, with only three pieces remaining. Next to it on the table are exactly 23 rocks, as well as a very wide wine glass and a very thin wine glass with the same volume of wine in each. Next to that is a partially constructed lego sunflower, a chess board showing a legal chess game in the midgame where a white bishop is checking the black king, and a DVORAK keyboard with the D and V keys swapped. On the wall there is a five panel instructional image on how to make toast, and as a poster showing the same church from four different angles, and another poster bearing a detailed diagram of the human eye. Also in the room there is a man sitting on a woman’s shoulders, both spinning sock poi. A man is doing a backflip off a podium bearing the presidential seal. On the ground there is a group of about a dozen people spelling out “OPEC” lying down with their bodies. There is a group of 5 people holding out one hula hoop each to form the olympic games symbol. The room contains dozens of people partying. Hidden among the crowd is a person dressed in a wheres wally costume. All of these features are plainly visible, with no AI artifacts.”
This is a much longer prompt, but it’s still only 250 words. Unsurprisingly, GPT fails:

When combined, almost every single element is worse than it was individually. The toast instructions was quite good on it’s own, but here it’s nonsensical. The jigsaw pieces are a warped mess, the keyboard doesn’t have enough keys, the backflippers hands are fusing with the crowd, etc.
No amount of regeneration with everyday resources is going to make this image work, without resorting to photoshop or whatever.
Conclusion:
I do not deny that AI image generation has gotten extremely impressive, and has improved rapidly in recent years. In 2021, generating an image like the last one from prompt would have been considered witchcraft. I do not doubt that in the coming years, AI image tech will continue to improve, and some of the prompts in this article will no longer stump AI image generators.
Perhaps I’m being naive, but I do not see current technology being able to pass something akin to my megaprompt, no matter how much computing power and scraped data you throw at it.
I think that sometimes when we see rapid progress, we forget just how big a claim something like “create any image” is. Hopefully this pushes back on that somewhat.
In UK copyright law they use the "moron in a hurry" metric. Basically, if a moron in a hurry would confuse two trademarks, there's a potential trademark infringement. This is what I think of the current generative-AI paradigm, all these images pass the "moron in a hurry" test, now it just needs to pass the "non-moron with time" test.
The backflipping secret service agent also appears to have a left hand where his right hand should be. What are they doing to those poor protective service teams?