
Eight reasons that existential risk estimates are so uncertain

What is the probability that all of humanity will soon go extinct? And if so, how?
In my previous article, I showed some data on how people, including experts, respond to this question. When you ask people to estimate the probability of human extinction from various causes by certain dates, their answers varied a lot, often by many orders of magnitudes. For example, below is the results from a survey on AI experts asked about the chance of extinction in the next 5 years. Note the log scale: they give answers from 1 in in 100 billion to 1 in 10.
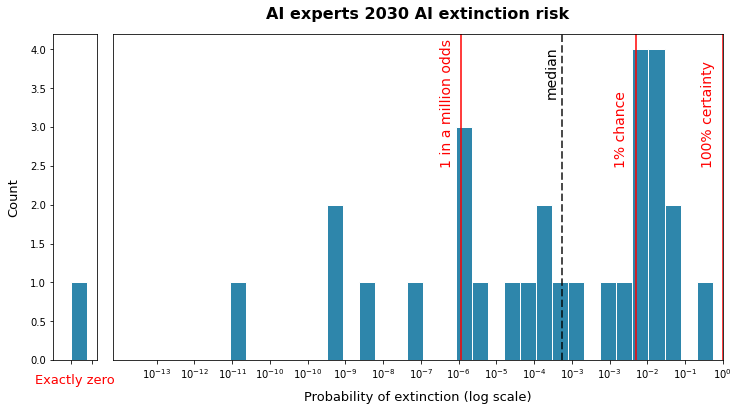
In this article, I want to give some guesses as to why the spread of answers is so high. I have put forward 8 factors that might contribute to this, but there are probably many more.
Made up statistics
Without looking it up, what is the population of Tanzania?
Most of you probably do not know this number off the top of your head. Given this state of lack of knowledge, you might answer this question with an answer of “I don’t know”, and not provide a numerical estimate.
In effective altruist communities, there is a cultural norm in favour of providing numerical estimates even in situations of high uncertainty or low information. The logic behind this is given by an old Scott Alexander blog post called “If It’s Worth Doing, It’s Worth Doing With Made-Up Statistics”, which is still cited regularly in EA spaces.
Essentially the argument is that you don’t know nothing about the population of tanzania: you know, for example, that it is not a trillion people, and you can be pretty sure it’s more than ten people. By providing an estimate, you inject some information into the discussion that is not previously there, which (the argument goes) will help you do a better job at decision making that just saying “I don’t know”. He highlights a commenters snappy summary of the argument as:
“Sometimes pulling numbers out of your arse and using them to make a decision is better than pulling a decision out of your arse.”
However, I would like to propose a corollary to this statement:
“If you are pulling a number out of your arse, your resulting estimate will probably be kinda shitty.”
I think it’s very important, anytime you do use “made up statistics”, that you are always aware of which results come from real data, and which are derived from made up numbers.
When it comes to a question like “what is the probability of a bioengineered pandemic wiping out humanity”, the use of “made up” numbers is unavoidable. When it comes to x-risk, there’s not really a binary question of “uses made up numbers” vs “doesn’t use made up numbers”. Every single x-risk estimate involves some level of ass-pulling.
“Made up numbers” go hand in hand with extreme uncertainty and widely varied estimates.
Uninformative empirical data:
I do not want to give the impression that existential risk estimates are completely made up, or based on zero empirical evidence. Often, some aspects of each threat will be studied in extensive detail.
My contention is that this detail is generally not particularly useful. To show this, I want to look at a threat which is close to ideal in terms of empirical knowledge, and explain why it is still nowhere near good enough. This is the case of terrorist attacks.
In this paper here,, researchers compiled a list of over 13000 terrorist incidents spanning a 50 year range, cataloguing how many deaths occurred in each one. They found that the data followed a clear statistical distribution called a power law distribution (which I will discuss in detail in a future article). This data can be directly translated into a probability: on the following graph the y-axis tells you the probability that a new attack will have X or more deaths, where X is a point on the x-axis:
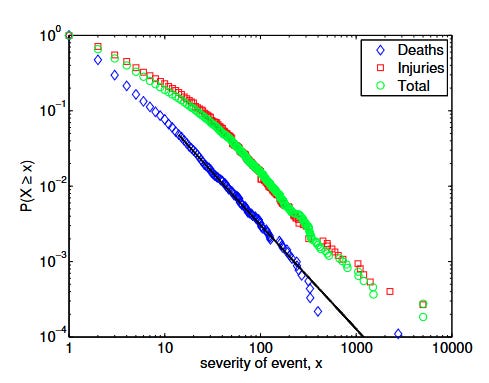
Great! We have thousands of data points, a clear trend, so all we have to do to find the probability of extinction is to to extrapolate out this trend out to the whole human race, right?
Here, I’ll do exactly that:
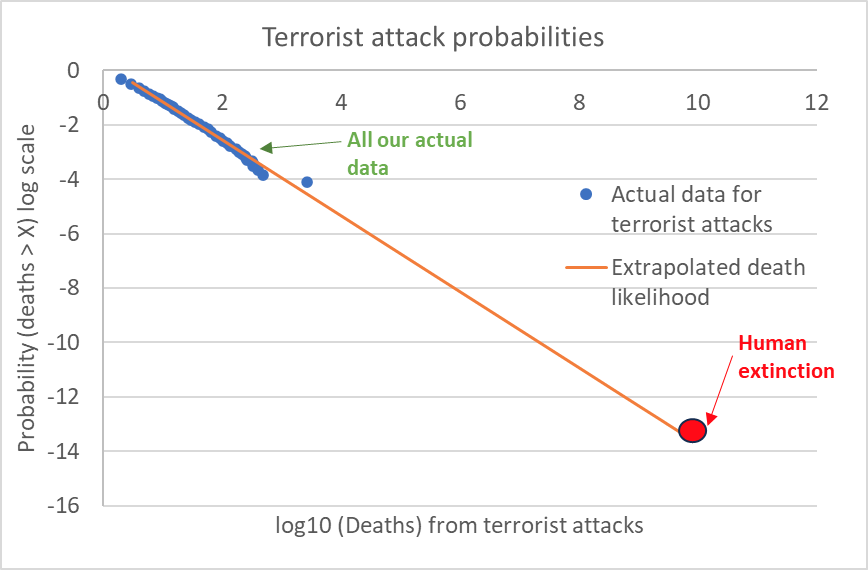
If you plug in the data fit, and extend it out like I just said, it will spit out the result that the probability of extinction from a terrorist attack in the next 50 years is 3 in a billion. I do not recommend you take this number very seriously.
First, just look at how far away from the actual data is from the point that we are extrapolating to! Just because we’ve established a trend that holds over 3 orders of magnitude, it does not mean it will keep holding for the next 7 orders of magnitude as well. It’s super common for data like this to hold to a pattern over a certain range, then fail for numbers above that. For example, if instead of the trend above being a line, it was very slightly curved downwards, it would result in a probability that was 1000 times or more lower than the original estimate.
Second, this assumes that the trend line will be constant over time. But in fact, they did an analysis and found that the slope varied significantly over the time period they are talking about, varying from an exponent of 1.5 to 3, which on a log-log curve makes a huge difference in a final estimate. We might expect that future technology and societal changes might significantly change the probability calculations, for the better of for the worse.
Given all these considerations, it’s not very surprising that estimates will vary over many orders of magnitude: even in a case like this where we have very relevant data, it’s just not good enough to be very informative.
Some disasters, like asteroid strikes and volcanic eruptions, will have enough data that we can have a decent empirical estimate at the odds of very dangerous events. But even in those cases, there is additional uncertainty as to how humanity will respond to everything. You can reliably guess the chance of a dinosaur-killing sized asteroid hitting the earth, but can you estimate the chances of humanity deflecting it? That latter question is crucially important, but we have no reliable empirical way to estimate it.
With AI risk, an analysis of “AI deaths” similar to the terrorist strike analysis above would not yield useful information, because there are way less AI deaths than terrorist deaths so you wouldn’t be able to establish a good trendline. If you did, it would probably spit out a very, very low probability of AI extinction. But that would be talking about current AI technology, not the future tech that people are worried about: there is massive uncertainty about where the technology will be in a few decades, as well as how society will react to it.
In summary, while empirical data can be used to inform existential risk estimates, for the most part they are not reliable in the regime which actually matters, leading to huge uncertainty in estimation attempts.
Unbounded estimation
In made-up estimates about real-world numbers, like “what is the population of Tanzania”, the potential error is somewhat limited by the reasonable bounds of the question.
You probably already know that the largest countries by population have like a billion people, so an answer of 20 billion is obviously nonsense. You could probably also say that you would have heard of it if Tanzania was a microstate like vatican city, so you can put a lower bound of like 10 thousand on there. So you only have like 5 orders of magnitude left to work with. With this range, there’s a limit on how wrong people can be on average.
On the other hand, a question like “what is the probability of human extinction from bioterrorism by 2050” does not have natural bounds. There are no hard upper or lower limits on how likely or unlikely the probability of an event can be1. The probability of the sun rising tomorrow is ridiculously high, meanwhile the probability of an entire person quantum teleporting a few kilometres away is finite, but the odds against it are so large that it’s actually physically impossible to write the number down.
The prior probability space of an x-risk outcome has a smaller range than the examples in the last paragraph, but it is still very high: I would say it puts the 5 orders of magnitude of the Tanzania example to shame. That doesn’t mean it’s impossible to get it right, but if you get it wrong, there are no guard rails in place to stop you being extremely wrong.
Anchoring bias
In 2023, the Forecasting Research Institute surveyed a number of different groups on existential risk estimates. One very interesting result came from a test of elicitation methods. I’ll quote in full:
“Participants in our public survey of 912 college graduates estimated a higher median probability of extinction by 2100 (5%) than superforecasters (1%) but lower than that of experts (6%). A similar pattern also emerged for AI-caused extinction (public survey participants gave a 2% probability, and superforecasters and domain experts gave 0.38% and 3%, respectively).
However, respondents of the same sample estimated much lower chances of both extinction and catastrophe by 2100 when presented with an alternative elicitation method. In a follow-up survey, we gave participants examples of low probability events—for example, that there is a 1-in-300,000 chance of being killed by lightning. We then asked them to fill in a value for “X” such that there was a “1-in-X” chance of a given risk.
….
Using that method, the median probability of humanity’s extinction before 2100 was 1 in 15 million. The median probability of AI-caused extinction before 2100 was 1 in 30 million. “
When asked about existential risk using their standard methodology, and asked in terms of percentages, the median respondent from the general public estimated a 5%, or 1 in 20 chance of human extinction. When asked in terms of odds, and when given examples of very unlikely events, their estimate dropped to 1 in 30 million. That’s a six order of magnitude drop!
I think that this massive difference is best explained by psychological anchoring, a well-established effect in psychology where uncertain estimates get “anchored” to the first number you hear, even if said number has questionable relevance to the situation at hand. For example, in one experiment, researchers found that participants would give a higher estimate of the number of african countries in the UN when they’d just seen a high number get rolled on a roulette wheel.
In this case, when thinking of “1 in N” odds, ones mind automatically goes to highly unlikely odds, like 1 in a million odds of winning a lottery. This is helped along by the examples of unlikely events like being hit by lightning.
On the other hand, you could argue that anchoring might also go in the other direction: after all, when we estimate percentages in every-day life, they are almost always between 1 and 100%. Really unlikely events are rarely expressed as percentages like 0.00001%, because it’s unwieldy and hard to parse: usually when an event becomes this unlikely we switch to odds. So by asking in terms of percentages, we might be anchoring people towards answers that are above 1%.
Regardless of which direction they go, this finding indicates that anchoring effects in existential risk estimates are potentially massive, and this extends to the uncertainty in the results: After all, at least one of these groups, and possibly both, must be many orders of magnitude off from the correct answer.
Humility bias
Imagine one day you corner your friend Ed on the street, and ask him the following question:
“Without looking anything up, what is the probability that the yellowstone supervolcano will undergo a caldera forming eruption in the next 50 years?”
He thinks for a second, and replies “Well, I don’t know much at all, about supervolcanoes. It seems like it’s a pretty unlikely event, but I think it’s important to be epistemologically humble. Given my lack of knowledge, it would be super overconfident of me to say that there was like a 99% chance that it won’t happen, so I will say 5%”.
Ed’s estimate is off by roughly 3 orders magnitude here. The actual answer, to the best of scientific knowledge is something like 1 in 14000., or 0.007%.2 What went wrong here?
The issue is that while Ed sounds like he is being epistemologically humble here, the actual principle he is following is this: “If I’m highly ignorant about the chances of an event happening, there must be greater than 1 in 20 chance of it happening”. This practically guarantees that he will massively overestimate the probability of low-probability events in general.
There are many things which I am highly uncertain of, but am nevertheless extremely confident won’t happen. For example, what is the probability that Vladimir Putin will slip on a banana peel and die next year? I wouldn’t be able to give you anything close to an exact number, but I know it’s extremely unlikely!
I see accusations of overconfidence pretty frequently around these questions, and I think if done badly, it will lead to situations like the one with Ed above, which could easily lead to large order of magnitude errors.
Take this example from an EA forum post on asteroid risk:
“Suppose diverting an asteroid into Earth is 10 times harder than deflecting it, and that deflection efforts are always successful. In that case, to think that developing deflection technology makes us safer, we would need to be confident that the risks from malicious use of the diversion technology are less than ten times as great as the natural risks from asteroid impacts. But this would mean being confident that the chance of malign use of the technology was less than 1 in 10,000 (0.01%) this century. This seems overly confident.”
Omnicidal humans are incredibly rare. What percentage of people, if presented with a button that caused an asteroid to strike the earth and kill billions of people, would actually press it? Probably less than 1 in ten thousand!
Now, factor in that actually running the asteroid deflection would be extremely expensive and require the cooperation of dozens or even hundreds of individuals: the odds that all or most of those people are in a conspiracy to kill billions of people seems astronomically low.
Then, we factor in that it’s actually pretty difficult to aim an asteroid precisely at a planet. The terrorists have to hit earth, while the defenders have to hit empty space: one of these is much bigger than the other. Putting all this together, it’s not at all overconfident to state that the chance of successful malign use is less than 1 in ten thousand.
The desire to avoid overconfidence can, in of itself, end up causing massive errors in ones estimations.
The difficulties of multi-step reasoning
In 2015, two months after Donald trump first declared that he was running for president and started leading in nomination polls, famed prognosticator Nate Silver estimated that there was only a 2% chance he would ultimately win the nomination. He laid out his reasoning on the eve of the first debate in an article titled “Donald trumps six stages of doom”.
The reasoning went like this: In order to win the nomination, a candidate has to make it through several different rounds of the primary process: ie, he has to make it through the first few states, then the “winnowing process” as other candidates drop out, then he has to persuade superdelegates to back him, etc.
Silver declares that he got his 2% figure from multiplying a bunch of different estimations together:
“So, how do I wind up with that 2 percent estimate of Trump’s nomination chances? It’s what you get if you assume he has a 50 percent chance of surviving each subsequent stage of the gantlet. Tonight’s debate could prove to be the beginning of the end for Trump, or he could remain a factor for months to come. But he’s almost certainly doomed, sooner or later.”
As Silver later acknowledged, this reasoning was wrong, and his initial estimate was far too low. The most likely mistake here was in not accounting for the correlation between different stages: was there really only a 50% chance that a candidate who made it past the “winnowing phase” would end up winning the most delegates, and then another 50% chance they would win over enough of the establishment to clinch the nomination? It did not really play out that way in reality.
The point of this anecdote is not to say that you shouldn’t split predictions into the various stages required for them to come true. Events that require multiple significant steps really are less likely in general than events that only require one or two. Presidential campaigns are long and arduous processes, and that really did decrease the chances of outsider candidates winning. If you’d ignored that, you would have ended up overestimating the chances of previous flash-in-the-pan candidates like Herman Cain.
Now, how does this problem apply to x-risk? Well, even in something like an asteroid strike, we still have to consider separately the odds that an asteroid is on course for us, the odds that we deflect it, and the odds that we find some way to survive the resulting blast. Something like AI risk is even more complicated, it is often modelled with multi-step conditional estimation. I don’t think it’s wrong to do these calculations… but the more of them there are, the easier it is for large errors to compound.
Incidentally, if you multiply lots of values together that each have some independent error in them, the result tends to be a lognormal distribution, a statistical distribution where values range over many orders of magnitude. So with this in mind, it’s not actually that surprising that an estimate involving lots of multiplied estimates would act in a similar way.
Other cognitive errors and biases
When talking about the difficulties here, let’s not forget old-fashioned biases.
For example, research on the availability heuristic shows that people will overestimate the likelihood of events that are easy to recall: for example they might overestimate the rate of shark attacks because they saw media reports or a scary shark movie. This could affect x-risk estimates: people might overestimate the chance of an asteroid strike because they watched an asteroid movie, or of an AI attack because they watched a movie about a killer AI.
The ostrich effect might result in people avoiding information that could lead to belief extinction risk is high, in order to avoid the distress of feeling doomed.
Normalcy bias could lead one to overestimate the probability that the future will be the same as the present, leading to an underestimation of risk: this is a common phenomenon that leads people to ignore the threats of natural disasters.
Narrative bias might lead people to overstate the importance of their own field of work: AI safety researchers may be motivated to believe that AI risk is high and they are saving humanity, rather than merely working on technical software problems.
This is nowhere near an exhaustive list. When these subtle biases are paired with the difficult nature of existential risk estimation discussed in the previous points. each one could possibly have a large effect on the final estimated result.
Groupthink:
Our estimates generally do not exist in a vacuum. They are influenced by the beliefs of others: and as a result one persons incorrect estimate can end up being outwardly influential on that of others.
We can imagine a case where a bigshot existential risk thinker is asked to estimate P(doom) in a report looking at a new cause like mirror bacteria, and they throw out a number like 5% as their final estimate.
A few other thinkers read this report, and now they have the number 5% in their mind. When asked, later, to provide their own estimate, they anchor or defer to the estimate of the original thinker, and end up clustering around the 5% mark themselves
Then everyone else in the community of these thinkers start thinking “well, all these smart people are saying it’s around 5%. So I should probably say the same thing, after all I’m not as much of an expert as all of these people.”. And pretty soon the number 5% becomes the consensus, “moderate” position. This doesn’t have to be a conscious decision, or an absolute one: there could be plenty of individual variation, but still be influence from the initial estimate.
Now, if bigshot thinker #1 is wrong (for some of the other reasons listed above), this wrongness has now spread itself, and become a widespread belief. Perhaps in an alternate universe where the original bigshot thinker said the answer was 0.1%, then that would have become the norm belief.
This is particularly nasty because it could lead to a false consensus, and lead to overconfidence in a groups consensus as a result. This is one reason why it’s good to have wider surveys which breaks out of possible intellectual bubbles by looking further afield.
Conclusion
This article has provided a non-exhaustive lists of reasons why existential risk estimates are really hard and conducive to order-of-magnitude errors and uncertainty. With all of these points in mind, it’s not surprising that estimates by smart people are so widely different from each other. If anything, you might expect the range of estimates to be even wider than what is seen in surveys.
I personally believe that the uncertainty in these estimates are so high that they are not informative, and are more likely to confuse than to elucidate. But I understand their appeal effective altruists, who find questions like “which threat is most likely to end humanity” to be crucially important considerations for moral goodness. In a future post, I will explain in more detail why I think these calculations may lead even the well meaning truth-seeker astray.
besides 0 and 1, obviously
converting from annual to 50 year
It’s confounding to me that there seems no limit to the speculative rabbit holes that will be described while the historical data and models clearly indicating societal collapse are ignored.
While speculative narratives dominate public discourse, academic institutions continue to use robust models to identify actionable policy changes required to stabilize global systems.
Cliodynamics is a transdisciplinary field that treats history as a hard science by applying mathematical modeling, complexity science, and big data analysis to historical societies.
Coined in 2003 by complexity scientist Peter Turchin, the name combines Clio (the Greek muse of history) and dynamics (the study of how complex systems change over time).
Instead of treating history as a series of unique, narrative events, cliodynamics looks for macrohistorical patterns, equations, and predictive trajectories governing why states grow, fracture, or collapse.
The 4.2kya event, the late Bronze Age collapse, and the fall of Rome all conformed to the model and were triggered by black swan events.
We seem distracted by theoretical black swans while ignoring hard data.
Societies have been hollowed out and made fragile. Fiscal collapse, civil war, and dark ages carry high s-risk.
On personal levels, this can be just as existential.
For a person, watching their social safety nets, economic stability, and community structures fail can be deeply terrifying and an existential crisis in its own right.
Throughout history, societies have exhibited patterns of growing increasingly fragile as wealth becomes highly concentrated and the structural center of a state erodes.
Perhaps this reveals an ambient anxiety of living in a failing state—where one's livelihood and personal survival are constantly threatened by systemic shocks.
This can create deep, chronic psychological distress, which psychologists frequently equate to personal existential crises.
It feels like this may be driving concern over existential risk.